Vision AI - Python
This guide will help you understand how to capture video frames in real-time using the VideoSDK, analyze them with OpenAI's Vision API, and publish the results back to the meeting. In this example, we'll capture an image from the video stream, send it to the OpenAI API for description, and publish the description as a message in the meeting.
Prerequisites
- Install necessary libraries:
pip install videosdk python-dotenv av openai - Create a
.envfile and add your VideoSDK token, meeting ID, and name:VIDEOSDK_TOKEN=your_token
MEETING_ID=your_meeting_id
NAME=your_name
OPENAI_API_KEY=your_openai_api_key
Code Breakdown
Imports and Constants
We start by importing necessary libraries and loading environment variables:
import base64
import asyncio
import os
from videosdk import MeetingConfig, VideoSDK, Stream, Participant, Meeting, MeetingEventHandler, ParticipantEventHandler, PubSubPublishConfig
from openai import OpenAI
from PIL import Image
from io import BytesIO
from dotenv import load_dotenv
load_dotenv()
VIDEOSDK_TOKEN = os.getenv("VIDEOSDK_TOKEN")
MEETING_ID = os.getenv("MEETING_ID")
NAME = os.getenv("NAME")
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
openai_client = OpenAI(api_key=OPENAI_API_KEY)
loop = asyncio.get_event_loop()
meeting: Meeting = None
participant: Participant = None
task: asyncio.Task = None
Capture Image
This function captures an image from the participant video stream asynchronously using async_capture_image, sends it to the vision_ai function for analysis, and publishes the result back to the meeting:
async def capture_video() -> str:
global participant
filepath = "capture_video.png"
# asynchronously capture image from video
img: Image = await participant.async_capture_image(filepath)
# Convert the image to a base64-encoded string
buffer = BytesIO()
img.save(buffer, format="JPEG")
image_frame = base64.b64encode(buffer.getvalue()).decode("utf-8")
await vision_ai(image_frame)
Analyse Image
This function analyse the given image and publish the result into meeting using gpt-4o and videosdk pubsub.
output will be stored in videosdk.txt file.
async def vision_ai(image_frame: str):
try:
# Prepare the messages for the OpenAI API request
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": [
"Describe the image",
{"image": image_frame, "resize": 768},
],
},
]
# Make a request to the OpenAI API to generate a description of the image
result = openai_client.chat.completions.create(
model="gpt-4o",
max_tokens=200,
messages=messages
)
# Extract the description from the API response
description = result.choices[0].message.content
print(description)
# Create a Pub/Sub publish configuration
pubsub_config = PubSubPublishConfig(
topic="CHAT",
message=description
)
# Publish the description to the specified Pub/Sub topic
await meeting.pubsub.publish(pubsub_config)
# Write the description into the file
with open("videosdk.txt", "w") as f:
f.write(f"Content {result.choices[0].message.content}")
except Exception as e:
print("Error:", e)
Event Handlers
Define event handlers to handle meeting and participant events:
class MyMeetingEventHandler(MeetingEventHandler):
def __init__(self):
super().__init__()
def on_meeting_left(self, data):
if task is not None:
task.cancel()
def on_participant_joined(self, p: Participant):
global participant
p.add_event_listener(
MyParticipantEventHandler()
)
participant = p
def on_participant_left(self, p: Participant):
if task is not None:
task.cancel()
class MyParticipantEventHandler(ParticipantEventHandler):
def __init__(self):
super().__init__()
def on_stream_enabled(self, stream: Stream):
global task, participant
if stream.kind == "video":
print("stream is video..")
task = loop.create_task(capture_video())
def on_stream_disabled(self, stream: Stream):
if task is not None:
task.cancel()
Main Function
Initialize the meeting and start the event loop:
def main():
global meeting
# Example usage:
meeting_config = MeetingConfig(
meeting_id=MEETING_ID,
name=NAME,
mic_enabled=False,
webcam_enabled=False,
token=VIDEOSDK_TOKEN,
)
meeting = VideoSDK.init_meeting(**meeting_config)
print("adding event listener...")
meeting.add_event_listener(MyMeetingEventHandler())
print("joining into meeting...")
meeting.join()
if __name__ == "__main__":
main()
loop.run_forever()
Running the Code
To run the code, simply execute the script:
python vision_ai.py
This script will join the meeting specified by MEETING_ID with the provided VIDEOSDK_TOKEN and NAME, capture video frames, analyze them with OpenAI's Vision API, and publish the results back to the meeting.
Feel free to modify the vision analysis logic inside the vision_ai function to apply different kinds of analysis or processing.
Output
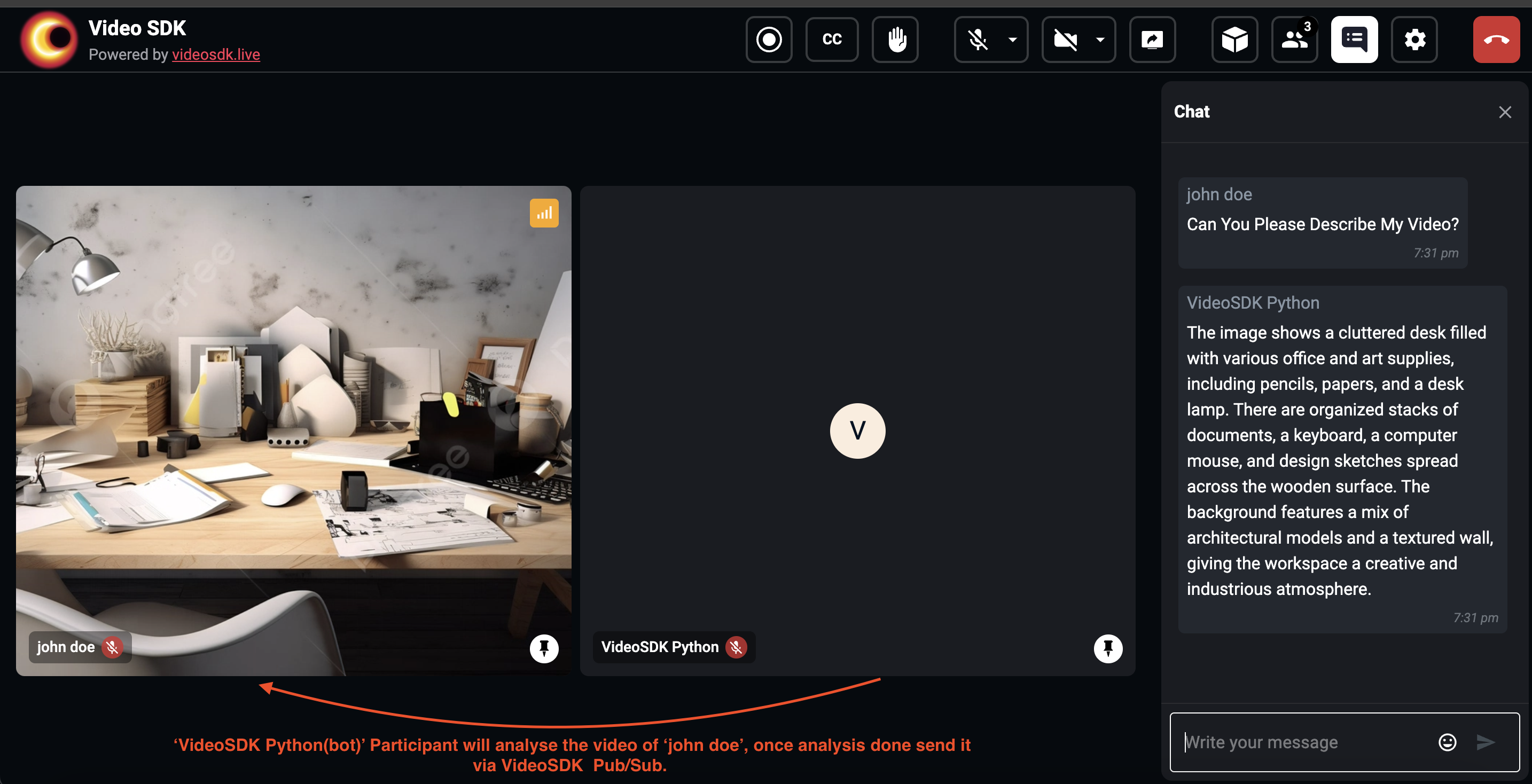
Stuck anywhere? Check out this example code on GitHub.
API Reference
The API references for all the methods and events utilized in this guide are provided below.
Got a Question? ![]() Ask us on discord
Ask us on discord

