Conversation Flow
The Conversation Flow component manages the turn-taking logic in AI agent conversations, ensuring smooth and natural interactions. It is an inheritable class that allows you to inject custom logic into the Cascading Pipeline, enabling advanced capabilities like context preservation, dynamic adaptation, and Retrieval-Augmented Generation (RAG) before the final LLM call.
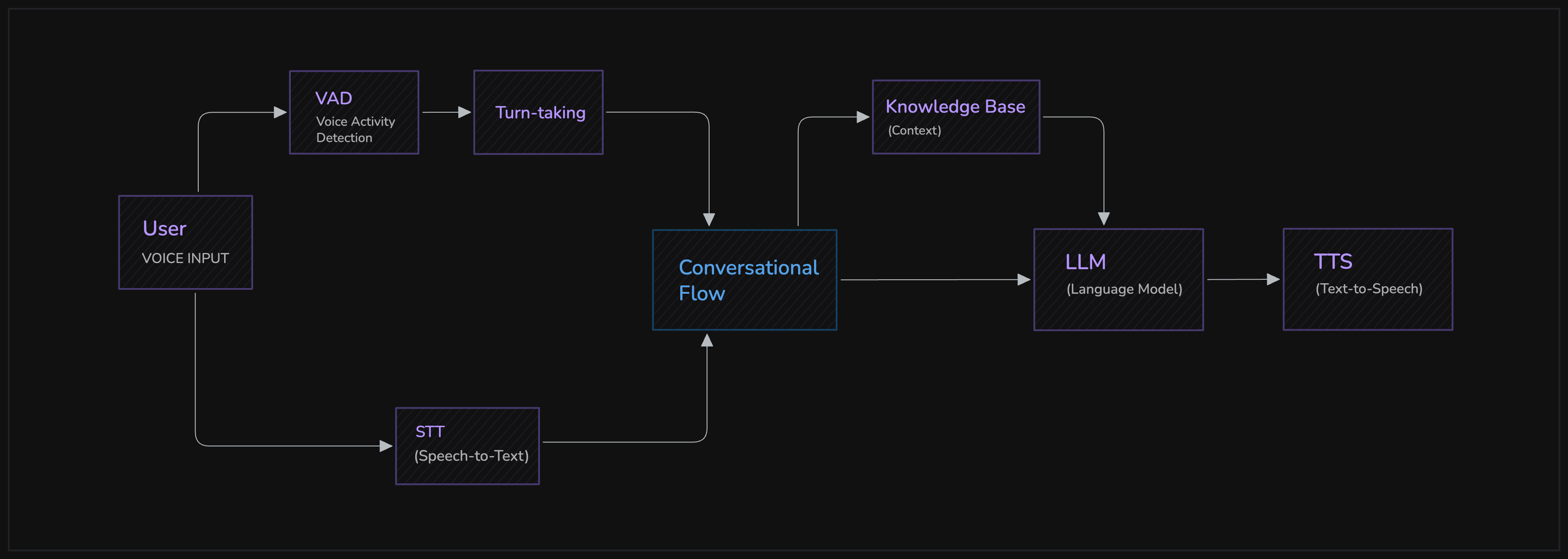
Conversation Flow is a powerful feature that currently works exclusively with the Cascading Pipeline ↗.
Core Features
The key methods allow you to inject custom logic at different stages of the conversation flow, enabling sophisticated AI agent behaviors while maintaining clean separation of concerns:
Core Capabilities
- Turn-taking Management: Control the flow and timing of agent and user turns
- Context Preservation: Maintain conversation history and user data across turns (handled automatically)
- Advanced Flow Control: Build stateful conversations that can adapt to user input
- Performance Optimization: Fine-tune conversation processing for speed and efficiency
- Error Handling: Implement robust error recovery and fallback mechanisms
Advanced Use Cases
- RAG Implementation: Retrieve relevant documents and context before LLM processing
- Memory Management: Store and recall conversation history across sessions
- Content Filtering: Apply safety checks and content moderation on input/output
- Analytics & Logging: Track conversation metrics and user behavior patterns (built-in metrics integration)
- Business Logic Integration: Add domain-specific processing and validation rules
- Multi-step Workflows: Implement complex conversation flows with state management
- Function Tool Execution: Automatic execution of function tools when requested by the LLM.
Basic Usage
Complete Setup with CascadingPipeline
The recommended approach is to use ConversationFlow with a CascadingPipeline, which handles component configuration automatically:
from videosdk.agents import ConversationFlow, Agent, CascadingPipeline
# First, define your agent
class MyAgent(Agent):
def __init__(self):
super().__init__(
instructions="You are a helpful assistant."
)
async def on_enter(self):
# Initialize agent state
pass
async def on_exit(self):
# Cleanup resources
pass
# Create pipeline and conversation flow
pipeline = CascadingPipeline(stt=my_stt, llm=my_llm, tts=my_tts)
conversation_flow = ConversationFlow(MyAgent())
# Pipeline automatically configures all components
pipeline.set_conversation_flow(conversation_flow)
Constructor Parameters
The ConversationFlow constructor accepts comprehensive configuration options:
ConversationFlow(
agent: Agent,
stt: STT | None = None,
llm: LLM | None = None,
tts: TTS | None = None,
vad: VAD | None = None,
turn_detector: EOU | None = None,
denoise: Denoise | None = None
)
To add custom behavior, you inherit from ConversationFlow and override its methods.
Built-in Methods
Core Processing Methods
process_with_llm(): Processes the current chat context with the LLM and handles function tool execution automatically.say(message: str): Direct TTS synthesis for agent responses.process_text_input(text: str): Handle text input for A2A communication, bypassing STT.
Lifecycle Hooks
Override these methods to add custom behavior at specific conversation points:
class CustomFlow(ConversationFlow):
async def on_turn_start(self, transcript: str) -> None:
"""Called when a user turn begins."""
print(f"User said: {transcript}")
async def on_turn_end(self) -> None:
"""Called when a user turn ends."""
print("Turn completed")
Automatic Features
- Context Management: The conversation flow automatically manages the agent's chat context. Do not manually add user messages as this will create duplicates.
- Audio Processing: Audio data is automatically processed through send_audio_delta(), handling denoising, STT, and VAD processing.
- Interruption Handling: The system includes sophisticated interruption logic that gracefully handles user interruptions during agent responses.
Custom Conversation Flows
RAG (Retrieval-Augmented Generation) Integration
Enhance your agent's knowledge by integrating RAG to retrieve relevant information from external documents and databases.
Benefits:
- Access external documents and FAQs
- Reduce hallucinations with real data
- Dynamic context retrieval
class RAGConversationFlow(ConversationFlow):
async def run(self, transcript: str) -> AsyncIterator[str]:
# Retrieve relevant context
context = await self.agent.retrieve_relevant_documents(transcript)
# Add context to conversation
if context:
self.agent.chat_context.add_message(
role="system",
content=f"Use this information: {context}"
)
# Generate response with enhanced context
async for response in self.process_with_llm():
yield response
See our RAG Integration Documentation for complete implementation.
Implementing Custom Flows
You can create a custom flow by inheriting from ConversationFlow and overriding the run method. This allows you to intercept the user's transcript, modify it, manage state, and even change the response from the LLM.
from typing import AsyncIterator
from videosdk.agents import ConversationFlow, Agent
class CustomConversationFlow(ConversationFlow):
def __init__(self, agent):
super().__init__(agent)
self.turn_count = 0
async def run(self, transcript: str) -> AsyncIterator[str]:
"""Override the main conversation loop to add custom logic."""
self.turn_count += 1
# You can access and add to the agent's chat context before calling the LLM
self.agent.chat_context.add_message(role=ChatRole.USER, content=transcript)
# Process with the standard LLM call
async for response_chunk in self.process_with_llm():
# Apply custom processing to the response
processed_chunk = await self.apply_custom_processing(response_chunk)
yield processed_chunk
async def apply_custom_processing(self, chunk: str) -> str:
"""A helper method to modify the LLM's output."""
if self.turn_count == 1:
# Prepend a greeting on the first turn
return f"Hello! {chunk}"
elif self.turn_count > 5:
# Offer to summarize after many turns
return f"This is an interesting topic. To summarize: {chunk}"
else:
return chunk
Advanced Turn-Taking Logic
For more complex interactions, you can implement a state machine within your conversation flow to manage different states of the conversation.
class AdvancedTurnTakingFlow(ConversationFlow):
def __init__(self, agent):
super().__init__(agent)
self.conversation_state = "listening" # Initial state
async def run(self, transcript: str) -> AsyncIterator[str]:
"""A state-driven conversation loop."""
if self.conversation_state == "listening":
# If we were listening, we now process the user's input
# and transition to the responding state.
await self.process_user_input(transcript)
self.conversation_state = "responding"
async for response_chunk in self.process_with_llm():
yield response_chunk
# Once done responding, go back to listening
self.conversation_state = "listening"
elif self.conversation_state == "waiting_for_confirmation":
# Handle a confirmation state
if "yes" in transcript.lower():
yield "Great! Proceeding."
self.conversation_state = "listening"
else:
yield "Okay, cancelling."
self.conversation_state = "listening"
async def process_user_input(self, transcript: str):
"""Custom logic for processing user input."""
print(f"Processing user input in state: {self.conversation_state}")
# Add logic here, e.g., check if the user is asking a question that needs confirmation
if "delete my account" in transcript.lower():
self.conversation_state = "waiting_for_confirmation"
Context-Aware Conversations
Maintain conversation history and user preferences to create a personalized and context-aware experience.
import time
class ContextAwareFlow(ConversationFlow):
def __init__(self, agent):
super().__init__(agent)
self.conversation_history = []
self.current_topic = "general"
async def run(self, transcript: str) -> AsyncIterator[str]:
# First, update the context with the new transcript
await self.update_context(transcript)
# The agent's chat_context (automatically managed) will be
# used by process_with_llm() to generate a context-aware response.
async for response_chunk in self.process_with_llm():
yield response_chunk
async def update_context(self, transcript: str):
"""Update history and identify the topic before calling the LLM."""
self.conversation_history.append({
'role': 'user',
'content': transcript,
'timestamp': time.time()
})
await self.identify_topic(transcript)
# Add topic-specific context (system messages are safe to add)
if hasattr(self, 'current_topic'):
self.agent.chat_context.add_message(
role=ChatRole.SYSTEM,
content=f"System note: The user is asking about {self.current_topic}."
)
async def identify_topic(self, transcript: str):
"""A simple topic identification logic."""
if "weather" in transcript.lower():
self.current_topic = "weather"
elif "finance" in transcript.lower():
self.current_topic = "finance"
Performance Optimization
To ensure the best user experience, consider the following optimization strategies:
-
Efficient Context: Keep the context provided to the LLM concise. Summarize earlier parts of the conversation to reduce token count and improve LLM response time.
-
Asynchronous Operations: When performing RAG or calling external APIs for data, ensure the operations are fully asynchronous (async/await) to avoid blocking the event loop.
-
Caching: Cache frequently accessed data (e.g., from a database or RAG store) to reduce lookup latency on subsequent turns.
-
Streaming: The run method returns an
AsyncIterator. Process and yield response chunks as soon as they are available from the LLM to minimize perceived latency for the user.
Examples - Try Out Yourself
We have examples to get you started. Go ahead, try out, talk to agent, understand and customize according to your needs.
Got a Question? ![]() Ask us on discord
Ask us on discord

